
시큐레이어 R&D 센터의 연구진 (김진 팀장외 4명, 문기중, 이수빈, 김원준, 문일주)이
‘도구 증강 LLM의 추론 과정 정제를 통한 컨텍스트 최적화 (Refining the Reasoning Process of Tool-Augmented LLMs for Context Optimization)’ 논문으로
「2025년도 한국인터넷정보학회 정기총회 및 추계학술발표대회」에서
‘우수논문상’을 수상 했습니다.
본 연구는 외부 도구와 상호 작용하는 도구 증강 LLM(Tool-Augmented LLM)이 복잡하고 긴 작업을 수행할 때 발생하는 ‘컨텍스트 누적 문제’를 해결하는 핵심 기술을 제안합니다.
LLM(Large Language Model)이 문제를 해결하기 위해 생성하는 내부 사고 과정(Internal Thought Process)은 다음 행동을 결정하는데 중요한 역할을 하지만, 다중 턴(Multi-turn)대화가
길어질수록 불필요한 정보가 컨텍스트에 누적되어 성능 저하(Lost in the Middle)와 연산 비용 증가를 야기합니다.
시큐레이어의 연구진은 이런 비 효율을 해결하기 위해, 사고 과정을 선별적으로 정제하는 새로운 방법론을 제안했습니다. 핵심은 다음과 같습니다.
- 실행된 도구 호출 관련 사고 : 해당 도구 호출을 유발하는데 사용된 사고 과정만 식별하여
간결하게 요약하고 정제합니다. - 미래 지향적 사고 : 다음 단계를 위한 계획 등 이후 턴에 필요한 정보는 그대로 보존하여
넘겨줍니다.
이러한 선별적 정제 능력을 학습시키기 위해, 연구팀은 관련성 점수를 기반으로 고품질 데이터셋을 구축하고, 핵심 의미를 유지하도록 유도하는 ‘가이던스손실(Guidance Loss) 함수를 적용하여
모델을 파인튜닝 했습니다.
실험 결과, 제안된 방법론의 효과가 명확히 입증되었습니다.
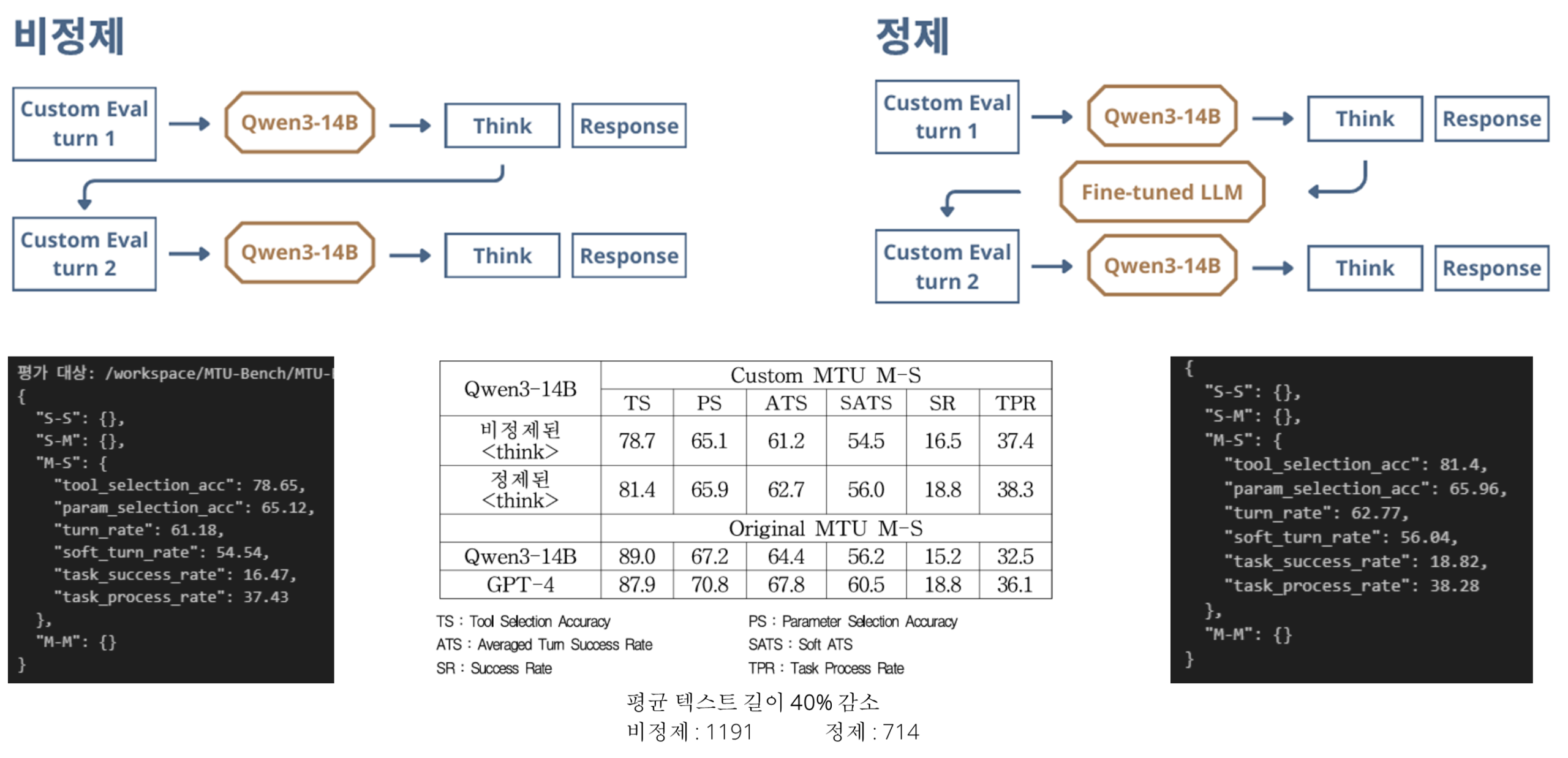
- 효율성 향상 : 평균 컨텍스트 길이를 약 40% 감소시키는 성과를 달성했습니다.
(1191.36 -> 714.37) - 정확성 향상 : 다중 턴 도구 호출의 정확성을 측정하는 핵심 지표인 성공률(Success Rate,SR)을 유의미하게 향상시켰습니다.
(비정제 16.5 -> 정제 18.8% on Custom MTU M-S)
앞으로도 LLM과 AI 보안 기술의 융합을 선도하는 시큐레이어의 행보에
많은 응원 부탁 드립니다~!
감사합니다.

